
Python Warm-up 02 Pandas
- Tung San
- Jul 27, 2021
- 1 min read

Updated: Jul 28, 2021

Pandas warm-up
# Preparing data
import pandas as pd
data = [50,50,47,97,49,3,53,42,26,74,82,62,37,15,70,27,36,35,48,52,63,64]
import numpy as np grades = np.array(data)
study_hours = [10.0,11.5,9.0,16.0,9.25,1.0,11.5,9.0,8.5,14.5,15.5, 13.75,9.0,8.0,15.5,8.0,9.0,6.0,10.0,12.0,12.5,12.0]
student_data = np.array([study_hours, grades])
df_students = pd.DataFrame({
'Name':[ 'Dan', 'Joann', 'Pedro', 'Rosie', 'Ethan', 'Vicky', 'Frederic', 'Jimmie', 'Rhonda', 'Giovanni', 'Francesca', 'Rajab', 'Naiyana', 'Kian', 'Jenny', 'Jakeem','Helena','Ismat','Anila','Skye','Daniel','Aisha'],
'StudyHours': student_data[0], 'Grade': student_data[1]}
)
df_students

# Get the data for index value 5 df_students.loc[5]

# Get the rows with index values from 0 to 5
df_students.loc[0:5]

# Get data in the first five rows df_students.iloc[0:5]

The loc method returned rows with index label in the list of values from 0 to 5 - which includes 0, 1, 2, 3, 4, and 5.
The iloc method returns the rows in the positions included in the range 0 to 5, integer ranges don't include the upper-bound value.
df_students.iloc[0,[1,2]]
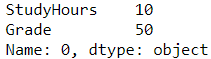
df_students.loc[0,'Grade']

df_students.loc[df_students['Name']=='Aisha']

df_students[df_students['Name']=='Aisha']

df_students[df_students.Name == 'Aisha']

Three different ways of filtering are used.
df_students.Name == 'Aisha'

A Series of Boolean object is given when df_students.Name == 'Aisha' is called.
df_students.query( ' Name=="Aisha" ' )
Use the DataFrame's query method for consistency. Although a string of command is expected as the 1st parameter.
Load data from file sourced online
import wget
http = "https://raw.githubusercontent.com/MicrosoftDocs/mslearn-introduction-to-machine-learning/main/Data/ml-basics/grades.csv"
wget.download(http)
df_students = pd.read_csv('grades.csv',delimiter=',',header='infer') df_students.head()

df_students.isnull()

df_students.isnull().sum()

df_students[df_students.isnull().any(axis=1)]

df_students.StudyHours = df_students.StudyHours.fillna(df_students.StudyHours.mean())

df_students = df_students.dropna(axis=0, how='any')

Descriptive Statistics
# Get the mean study hours using to column name as an index
mean_study = df_students['StudyHours'].mean()
# Get the mean grade using the column name as a property (just to make the point!)
mean_grade = df_students.Grade.mean()
# Print the mean study hours and mean grade
print('Average weekly study hours: {:.2f}\nAverage grade: {:.2f}'.format(mean_study, mean_grade))

# Get students who studied for the mean or more hours df_students[df_students.StudyHours > mean_study]

# What was their mean grade?
df_students[df_students.StudyHours > mean_study].Grade.mean()

passes = pd.Series(df_students['Grade'] >= 60)
df_students = pd.concat([df_students, passes.rename("Pass")], axis=1)
df_students

print(df_students.groupby(df_students.Pass).Name.count())

print(df_students.groupby(df_students.Pass)['StudyHours', 'Grade'].mean())

# Create a DataFrame with the data sorted by Grade (descending)
df_students = df_students.sort_values('Grade', ascending=False)




Comments